
This quote from Danny Ayers in the social-network-portability group is spot on and goes a long way to help explain why our approach to document-driven visualization is the best way to integrate:
Architecturally, there are at least two big advantages in taking this
approach [of import/export to common portable formats].
When we have an environment which contains N different formats/
APIs which can express the social information, either we need
N^2 different converters to enable interop *or* we can map to a common
model, and just need N different parsers/serialisers - still
non-trivial, but a lot easier. The second advantage, which is the
reason an RDF-backed is appropriate, is having the flexibility to
compatibly include whatever (other) information you like in the common
model, beyond the limitations of the typical individual formats/APIs.
Check Tim Berners-Lee's FOAF [6].
Thursday, December 20, 2007
On API Integration
Wednesday, December 19, 2007
all.my.base
I wanted to see if I could remember/find all of the web spaces where I have a profile and/or social network:
Linked In (as kevincurry)
del.icio.us (as prestidigital)
facebook (as kmcurry)
Last.fm (as prestidigital)
My Space (as prestidigital)
Yahoo! (as prestidigital)
OpenId (as kevincurry)
Simpy (as prestidigital)
Slashdot (as prestidigital)
TED (as KevinCurry)
Orkut (as Kevin Curry)
MSN (as hokiestoked)
AOL (as hokiestoked)
Update 01/06/08 - I'm updating this list in the butter room
Tuesday, December 4, 2007
Net-centricity v. Social Networking
Danger Room Editor, Noah Schachtman, has a rather interesting article on this topic in the Dec. 2007 print issue of Wired, 15-12. The main theme is the juxtaposition between net-centricity and social networking (although not exactly the social networking we know through Web 2.0 popular culture). The message about net-centricity is that it is highly effective as a destructive, lethal capability while social networking is better at stability operations and counter-insurgency. Some of the most advanced social networking groups in Afghanistan are just starting to step it up with computer hardware and software, I reckon to enable things like social bookmarking, collaborative placemarking, network analysis, pattern matching, and the like. But the focus in Iraq and in general is on personal interaction, almost eschewing technology. The irony of ironies is that our military has an excellent solution to a problem it does not currently have (fighting big wars with nations and dictators), while the terrorists and insurgents have swiftly mastered the technology domain of modern social networking - email, cell phones, text messages, chat, forums - and the military is reportedly now most successful resorting back to low-tech, human/psychological solutions. Not coincidentally or surprisingly, there is some heated debate about the role of social science in military operations. My interest is in the heart of the matter...the balance between communication technology and human interaction, particularly when technology gets in the way or solves the wrong problem. The insight in the Wired article is that, technically speaking, a better application of IT to the military's current and future challenges related to stability ops and counter-insurgency, as previously inferred, is closer to Web 2.0 social networking and collaborative read/write web technologies, web services, pub/sub and the like. I would go so far as to project the need onto the whole of government and civic life - federal, state, and local.
Monday, November 19, 2007
Net-centricity
I received a forwarded email from a colleague entitled "DoD seeks net-centricity help." I found a copy here. It seems from this article, at least, that they do in fact have a problem articulating their message. I also suspect they aren't talking to the right...vendors. Mr. Montemarano is sparse on specifics and fails to bound the problem. I know it's just a syndicated news article, but it's the message I received. (Ironic, isn't it?) What do you want me to consider? He says he wants vendors to offer pub/sub. Ok, great. Done. But, what about security? Presumably that is important to DoD. What about the Army's mobile, ad-hoc requirements for FCS? Net-centricity is a broad concept. Some argue that it also frames the problem in terms of technology and not people. There is certainly something to that. As a career student of computer-supportive cooperative work (CSCW) and human-computer interaction (HCI), I usually defend that position. (Consider the case here, where news with the wrong message has been successfully syndicated to a wide audience. Tech did it's job.) But sometimes it is just about the technology and I think that is the case with DoD net-centricity in the way I infer here. I would agree that vendors are not implementing what Mr. Montemarano seems to need. DARPA invented the Internet. It was an amazing technical feat. Communication-wise it was about as complicated as "Hi." But DARPA must have become a one-hit wonder in the telecom domain. What Mr. Montemarano wants is Web 2.0. And he can have it. Want is not happening is that no one is seriously considering how to get Web 2.0 done in what are rigidly constrained environments inside DoD. And O' Reilly's original essay on Web 2.0 isn't without flaws. "Wisdom of Crowds" can also lead to "Group Think" and gross disinformation. Mr. Montemarano, my name is Kevin Curry. I work for a company called Bridgeborn. We have offices in Virginia Beach, VA, Arlington, VA, and Savannah, GA. Give me a call.
Thursday, November 15, 2007
On Addressability of Data on the Web
I don't understand data sharing solutions that require centralization of data stores. Centralization is an organizational artifact, not a technical one. "The way to solve this is...everyone stop putting you data there and start putting it here." By the very nature of the web, this requirement will never be fully satisfied. There will always be something not in the "master database" that is relevant. And how do you consume data from multiple sources, i.e., multiple perspectives (ex., operational, financial, organizational)? Centralization is seldom even possible, by design, in classified environments and highly improbable when sharing data potentially leads to losing your budget. If data exists on the web and needs to be shared then the way to share is clearly pub/sub; to syndicate query results over HTTP. Probably, but not necessarily, XML will be used to carry data. Technically this should be a no-brainer. Wrap database stored procedures with methods on a Web Service and point to them with URLs. Everything we share on the web we share over HTTP using URLs for addressability. Addresses are fundamental to how data is managed in computers down to the hardware. Why should data on the web be any different? They aren't:
[Note: These links are illustrative. They don't work]
- GetConsumerOpNodesByCountOfIER
Returns an Xml Node containing the list of Consumer Operational Nodes and their IER counts, ordered by count - GetConsumerSysEntitiesByCountOfIER
Returns an Xml Node containing the list of unique System Entities ordered by number of IERS for which the SysEntity is used as a Consumer - GetConsumerSysNodesByCountOfIER
Returns an Xml Node containing the list of Consumer System Nodes and their IER counts, ordered by count - GetMissionThreads
Returns an Xml Node containing the list of unique Mission Threads - GetMissionThreadsByCount
Returns an Xml Node containing the list of unique Mission Threads by count of threads - GetMissionThreadsForOpNode
Returns an Xml Node containing the list of unique Mission Threads in which the given OpNode participates. - GetOpActivities
Returns an Xml Node containing the list of unique Operational Activities
Sidebar: Just like hardware, data addresses aren't particularly people-friendly. Look to the ideas behind semantic web to help with that.
Monday, November 12, 2007
Form-driven Editors and Language as Cognitive Artifacts
I was recently noodling in an Access database, creating queries. By default the "New Query" dialog steers users to a form-driven editor. It takes a couple of clicks to get to a text editor for writing SQL.
When writing SQL, at least, I'd much prefer the text editor by default. The reason is that the form editor slows me down at a very fundamental level. It's not as if I'm a coder with a chip on my shoulder about graphical code generators. Far from it. I can think of at least two that are quite handy at what they do [1, 2]. But with a language like SQL it's always going to be easier to learn how to speak the language than learn how to use a proprietary GUI. Even if Access was the only database technology I ever used (which is not the case), I know intrinsically that SQL is the right way to query a database and a form editor is the wrong way to query a database. The reason is that the act of querying a database is, at its core, an act of language expression. Filling in a form and dragging boxes around are acts of interaction that get in the way of expression...of me telling the computer what I want it to do.
This must be the inherent lesson from Donald Norman's theories on cognitive artifacts. It's interesting that I found this article by him just now. It says:
"And of all the artifacts that have aided cognition, the most important is the development of writing, or more properly, of notational systems: number systems, writing, calendars, notational systems for mathematics, engineering, music and dance."
Sunday, October 7, 2007
Thursday, October 4, 2007
Not An All Or None Situation
Document-driven visualization represents a disruptively powerful innovation for visualization interoperability. It means that we can treat visualization in the same way that we treat the clear majority of data on the web.
But I'm having a mini-reawakening to the bigger picture in which we see the value in APIs and ultra-lean (and more secure) data transfer. When we tie into simulators we still use XML to configure the system, but in a way that tells it to use the API to connect to values directly as they come off a TCP/IP socket connection. The same is true for online collaboration. The object in these cases is to move data efficiently and reliably. There's no need to pull in all the DOM overhead and seldom any need to perform transformation of the data. (But even complex rules for converting Attribute types can be encoded into Objects that are then configurable through Reflection, Serialization, and ultimately XML. We call them "AttributeConverters.") The other network protocols (TCP/IP, UDP...not really FTP) contribute by giving us a lot more flexibility in terms of quality of service. Again, OO fundamentals are key. Object Reflection means we can get and set any attribute value in a standard way...in the API. Any integration more complicated than that usually indicates that our core visualization capability is missing something. Ultimately we want to move closer to the GPU...I think...dual core processors also represent a new (finally stable) option for better performance laptops and PCs.
I digress. Document-driven viz is super neat, but it isn't everything. I suppose I'm just echoing a common theme in life. Not a Panacea. Not a Silverbullet. Not A Cure for World Hunger. Just the best thing I've seen in my brief career.
Wednesday, October 3, 2007
Thoughts on secure data publishing and transformation governance and best practices
I'm not a security guy, so maybe I'm out a limb here. Douglas Crockford recently called the DOM and huge security problem. I'm looking at a huge traceability and lack-of-symmetry problem. The problem I usually run into in big enterprises is not with permission to trace data, but the complete in ability to do so. When people can't trace data back to sources and when transformation processes are asymmetrical, it becomes extremely, exhorbitantly difficult to make sense from information; V&V goes out the door.
Claim:
Data exports should pass metadata describing, at minimum, their immediate source, and any transformation applied by that source when producing the data. This metadata forms a singly-linked, directed list from data targets to their sources (ex., from an Excel spreadsheet back to a System Architect model). The link list can be followed only by persons and systems having clearance to do so.
Motivation:
Better traceability and symmetry in the data transformation and publishing process
Specification for metadata:
Required field: URL for source
Required field: Security Classification of source
Required field: Security Classification of metadata and traceability permission
Required field: Timestamp
Required field: Author, publisher name
Optional field: Name (aliases?) of source
Optional field: Name (aliases?) of transformation
Optional field: URL for transformation, when used (bad practice to not include when present)
Optional field: Description of source
Optional field: Description of transformation
Technical Requirements:
It is the producer's responsibility to describe itself by placing metadata into the exported target's DOM. This is not a "must" requirement. Data producers have the right to be anonymous.
Use Cases:
Cleared receivers of data can trace data back to the data's source by following a hyperlink to the source, or to metadata when the source is incapable of acting as an Internet asset. The link chain can be followed as long as the tracer has clearance to go to the previous node, i.e., to visit a URL. The burden for granting or denying access to URLs is already maintained by existing systems (ex., Web server permissions, CAC).
Tuesday, September 18, 2007
Document-Driven Visualization
Alright, here's the flow on document driven visualization. Documents are the lifeblood of the Internet. Right now everything we experience on the web is tied to documents. If it's Flash it's a document...instructions that tell the Flash engine what and how to render. HTML is a document. Any markup is a document. Even if it's not XML...if it's data, it's a document. Don't argue it, just accept it. Be okay with it because documents are just written communication. What are we doing when we use computers to collaborate if not communicating? So, it stands to reason that if visualization is going to thrive on the Internet it had better come to terms a document model...The Document Object Model, to be specific.
So I realized that the DOM makes for an ideal match to visualization, as I was taught it. I learned visualization programming using SGI's IRIS Performer. Performer was a...no, THE rich, powerful API driving almost every immersive virtual environment on the planet in the late, late 90s (maybe it still is). A central concept in Performer is the Scene Graph. A Scene Graph is made of Nodes. Nodes have Parents and Children. Graphs of Nodes can be Traversed. When Nodes are visited (during Traversal) they are evaluated and sometimes modified. The way we created and manipulated an immersive virtual environment was to add, remove, modify, and traverse the Nodes of a Scene Graph. So, it could be said that the complexity of writing any visualization application can be reduced to the repetitive execution of these operations over these Objects in performance of some domain-specific task. Well, it wasn't sooo easy, but the concept was really starting to gel.
Then I learned about a couple of really handy patterns from the Object-Oriented Paradigm that were in the Java core language. "Handy" doesn't do them justice, in fact. To me, Reflection and Serialization are the most important aspects of OOP. In a nutshell, Serialization is the ability for Objects to write themselves (or be written) out to text (XML) and Reflection is the ability for an Object's Attributes to be Get and Set by name.
Scene Graph has Nodes. DOM has Nodes. (Scene Graph is a Graph. DOM is a Tree. Turns out this is not a constraint that matters.) The fundamental operations on a Scene Graph of Nodes are the fundamental operations on a DOM Tree. Nodes are Objects. Even operations are Objects. Objects can be Reflected upon and Serialized to XML. Visualization Objects can be Reflected upon and Serialized to XML. Visualization is a Document. I don't know if that is a straight line but it seems pretty damn solid to me.
This is powerful. Visualization (and interaction) can be published. Visualization (and interaction) can be transformed. Visualization (and interaction) is interoperable. Visualization (and interaction) can be mashed up. Visualization gets the Internet. (Visualization gets natural language?)
Here are some other important factors:
A. We don't serialize everything to XML. Very rarely do we need to spell out all the vertices and normals of a geometry. 3D models do not need to be XML. To me expressing geometry as XML (some is okay) is like expressing the 0-255 value of every pixel in a bitmap. Do what HTML does with images:
"img src="url/to/image.jpg""
"Model url="url/to/model.lwo""
B. Driving visualization with APIs is powerful and there are plenty of occasions for it. But point-to-point API integration does not scale. You want graphs and maps and charts. Prefuse does graphs. Earth does maps. ChartFX does charts. Have fun coding. Instead, programs should use XML as a standard input/output format. Then at least integrators can use ubiquitous technologies to move and transform data from program to program. Visualization programs can even be written by other software programs. It's just rules producing markup fed to a render context. All of this reminds me of the Unix operating system. But with apps and APIs we still aren't getting to the heart of the matter. Apps and APIs are laden with cognitive artifacts for both end users and developers. Whether we are talking about the presentation and interaction layer or the business layer, apps and APIs all have their own ways of doing things. And APIs really only open up apps to developers (i.e., specifically those who take the trouble to learn the API). XML opens apps to developers (i.e., most any developer who understands how to work with XML) and other apps. We're not so much trying to bridge apps with document-driven visualization. Instead, we're trying to bridge visualization across two extremes. At one extreme is the render context...the canvas on which the computer paints. At the other extreme is the human mind; the mental models we construct, the metaphors we understand. Perhaps it is more accurate to say that we are trying to enable visualization through communication medium connecting two points. There is a language that we will express to describe what we want to see and how it should be rendered and behave, regardless of any tool set or application.
C. Document-driven visualization does not make visualization slow, inefficient, or a resource hog. SAXParsers are lightning fast. XML is highly compressable. Either the render engine is fast or it isn't, but that's not XML's fault. We're only using XML to pass instructions to the engine. If anything, the Reflection and OO in general adds overhead. But getting hung up on clocks and RAM as matters of efficiency is to lose site of all the inefficiency created by so much heterogeneiety. The benefits avoid the costs of having low interoperability and far outweigh the costs of clock cycles and memory.
Ok, that's enough for now.
Update 09.04.08: I have since realized that document-driven can "well-formed Unicode text," and not necessarily XML. JSON is a good example of an alternative. Of course there are trade-offs, too. I considered that here
Saturday, September 15, 2007
Tag Bundling
Everything I "know" about USAID is here:
http://del.icio.us/prestidigital/USAID
All my links to USAID data are here:
http://del.icio.us/prestidigital/USAID+data
Friday, August 24, 2007
More Examples of the "Next Generation?"
MapQuest -> Google Maps
communities -> social networks
postal address -> geocode
network backbone -> data and services backbone
website hosting -> web services hosting
3rd Generation Web
personal web sites -> blogging -> personal publishing
Background:
Tim O'Reilly's 2005 report "What is Web 2.0? Design Patterns and Business Models for Next Generation Software" introduced me to the subject of Web 2.0 (almost a year after it was written). In this article he showed the results of a brainstorming session where members of O'Reilly Media and MediaLive International paired examples of (then) current generation with the next generation.
I think there are a few flaws in the logic that extends from the original list of pairs. For example, Google ending up buying DoubleClick in April of this year for $1.3B U.S. DoubleClick was obviously alive and kicking and the transition from Web 1.0 to Web 2.0 was not the result of any generational (read paradigm) shift, but rather one hell of a business deal. And I'm not sure declaring evite "out" and upcoming "in" is either right or fair. Evite has a great brand and they do a good job of promoting and coordinating an event. They could easily choose to open up their data and services and compete on other portal features like localized listings (that's what you get when you make everyone's data public). And guests still like getting a nice invitation. It's just not paper. MapQuest, on the other hand clearly doesn't get want users want from a map services. Usability is poor and it looks more like they are in the business of promoting offers. Meanwhile Google invested in mapping, invigorating it into the mainstream and always innovating into ever more seamless application of their service.
As a matter of reference I have copied the original list of pairs here:
Quote:
In our initial brainstorming, we formulated our sense of Web 2.0 by example:
| Web 1.0 | Web 2.0 | |
|---|---|---|
| DoubleClick | --> | Google AdSense |
| Ofoto | --> | Flickr |
| Akamai | --> | BitTorrent |
| mp3.com | --> | Napster |
| Britannica Online | --> | Wikipedia |
| personal websites | --> | blogging |
| evite | --> | upcoming.org and EVDB |
| domain name speculation | --> | search engine optimization |
| page views | --> | cost per click |
| screen scraping | --> | web services |
| publishing | --> | participation |
| content management systems | --> | wikis |
| directories (taxonomy) | --> | tagging ("folksonomy") |
| stickiness | --> | syndication |
Wednesday, August 22, 2007
More Observations in Social Network Visualization

My del.icio.us network with a hidden back graph:

My network with labels hidden:

My network with labels and edges hidden:

My network with the back graph in high contrast:

Least relevant connection in my network?
 One of the outlying nodes is a case of mistaken identity, i.e. the wrong user was added to a friend's network and neither of us know this person. The other outlying node is not a person, but a group. The group is not really used by anyone.
One of the outlying nodes is a case of mistaken identity, i.e. the wrong user was added to a friend's network and neither of us know this person. The other outlying node is not a person, but a group. The group is not really used by anyone.Monday, August 20, 2007
social-network-portability on Google Groups
The most active topic is "On Centralisation vs De-Centralisation," including separate threads. But there are clear sub-themes running as well: identity, privacy, property, and language protocol. I detected a coincidental cross-current of the property issue on Tim O'Reilly's blog today. But it seems to me that the "Thoughts..." starts with the assumption that cooperating parties are going to do the right things - "assumes" not "takes for granted." At least, it is assumed that this thing is going to be developed one way or the other and the key is to seize the moral high ground by taking charge of the discussion of how, exactly.
Social Network Portability is "A Good Thing."
Tuesday, August 14, 2007
Tuesday, August 7, 2007
Experiences and Observations in Network Visualization
 I built a web app called g.licious that uses graph layouts to visualize relationships in del.icio.us data. I built the tool mainly to test our graphing package in Bridgeworks together with AJAX and web services. Visualization of relationships using graphs is certainly not new. In fact, there has been plenty of criticism of this approach. Indeed, the criticism is not without basis. Regardless, people keep doing it. The reason we keep doing it is because the approach itself is quite sound. Results happen. How people choose to use graph viz is another story. So what is it that makes good graph viz and bad graph viz? Well, I have to say that I can't pretend to know even a tiny fraction of what Jeffrey Heer and Stuart Card know. They defined graph viz. They've studied it more than anyone I know of and that's how I learned. Still, I think my experience has taught me a few things that are worth recording. In the spirit of visualization, I thought I'd start with a few observations from g.licious.
I built a web app called g.licious that uses graph layouts to visualize relationships in del.icio.us data. I built the tool mainly to test our graphing package in Bridgeworks together with AJAX and web services. Visualization of relationships using graphs is certainly not new. In fact, there has been plenty of criticism of this approach. Indeed, the criticism is not without basis. Regardless, people keep doing it. The reason we keep doing it is because the approach itself is quite sound. Results happen. How people choose to use graph viz is another story. So what is it that makes good graph viz and bad graph viz? Well, I have to say that I can't pretend to know even a tiny fraction of what Jeffrey Heer and Stuart Card know. They defined graph viz. They've studied it more than anyone I know of and that's how I learned. Still, I think my experience has taught me a few things that are worth recording. In the spirit of visualization, I thought I'd start with a few observations from g.licious.
Starting with the basics...here is my del.icio.us network:
The graph layout is called Radial Tree. Radial Tree is a prototypical "degrees of separation" view shown as concentric circles about a center point of interest. Here I'm in the middle ("prestidigital"). The first circle of names around me are the friends in my immediate network. They are connected to me by the green lines. Beyond that are friends of my friends. They are connected by blue lines. The gray lines are called the "back graph." It shows which of my friends and friends' friends know each other. My networks has some quirks. At least one person has two del.icio.us identities. Another name was added as a case of mistaken identity. (Those are topics for another discussion.) This view shows my extended network in one place. It shows me relationships among my friends. That's somewhat useful and interesting. It's more than the del.icio.us network view provides. But that kind of value added is a nice-to-have, not a must-have. The real value of a view like this comes when I use it as a foundation on which to add layers of information, when I use it to ask questions. Here is my network with "traffic": In this view nodes representing my friends are sized according to how many links I have sent them using the del.icio.us for: tag. But then...why do I really care to see where traffic in my network is going? Well, this view answers the question "how much?" So maybe I and my are placeholders for distributor and supplier, producer and consumer, seller and buyer, caller and callee. Conveniently, one of the keys to success with this view happens to be the fact that I have a small network. What happens when I have a HUGE network? Hold that thought. Suffice it to say now that what's important isn't necessarily how much I can see at once, but rather what I can know based on what I see. Navigability through levels of detail is also important. But for now, I want to keep it simple. There's a lot I can learn, pro and con, from this tiny little set of relationships.
In this view nodes representing my friends are sized according to how many links I have sent them using the del.icio.us for: tag. But then...why do I really care to see where traffic in my network is going? Well, this view answers the question "how much?" So maybe I and my are placeholders for distributor and supplier, producer and consumer, seller and buyer, caller and callee. Conveniently, one of the keys to success with this view happens to be the fact that I have a small network. What happens when I have a HUGE network? Hold that thought. Suffice it to say now that what's important isn't necessarily how much I can see at once, but rather what I can know based on what I see. Navigability through levels of detail is also important. But for now, I want to keep it simple. There's a lot I can learn, pro and con, from this tiny little set of relationships.
This view of my network shows communities of interest:
At the bottom half of the view are researchers and librarians I know that work in the same library. At the top, those who are closest to me are in fact office colleagues, two co-founders of my company, my wife, and one of my closest friends. That seems to say something important. (The graph layout is called a Force-Directed Graph. The general idea is that the edges act like springs.) Now, the thing with this bit of knowledge about my graph is that it seems hard to generalize beyond a specific set of circumstances that occur here. The reason I know how to interpret his view is because it's my network. People in my network might also know how to read it. But what if the relationship is not people?
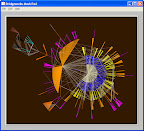
Here is a view of my del.icio.us tags:
Now, this isn't the greatest view in the world, but I have to keep mind a few things: 1) I made it in a hurry, 2) the picture is really a screen capture of an interactive 3D visualization that is easily manipulated with a mouse, keyboard, or clever software, and most importantly 3) there are plenty of people that can easily identify clusters of keywords that belong together. WSP+music+band+setlist+Virginia locates the setlists from Widespread Panic concerts I attended (in my home state). The dates 2006 and 2007 describe "when" and each points to the show I saw here that year. DoD-.mil-software-certification points directly to information about Department of Defense policies and procedures for getting software certified on .mil networks. There are several other clear relationships in the larger spline to the right.
Ok...so there's a lot to consider here and I'm getting tired. More later... The images here aren't great because they are small. I tried to link to my Picasa web albums. Ironically that didn't work in Blogger (both are owned by Google...again, another story). So here's a direct link.
Sunday, August 5, 2007
Third time may not be the charm
This is technically the third blog I've created. The first was my Slashdot Journal. I'm not really sure why I stopped writing there. It's not the best interface and you can't feed it. Then I liked what my friend Todd Wickersty was doing with some of his sites using Word Press. So installed a XAMPP and WordPress on my laptop and wrote a few things in there. Word Press is great (and so is XAMPP). I intended to continue there but never got around to moving to a more accessible infrastructure via some hosted site. So here I am at blogger.
